QuantHub Architecture
Functionality Highlights
QuantHub offers a full-stack solution for statistical agencies or any other organizations that create, process, and periodically publish data products. Powerful QuantHub features help create data products with minimal effort and effectively support them throughout the entire lifecycle. You can leverage automation tools that make a part of the solution to optimize the routine of data owners and analysts by avoiding repetitive manual and error-prone tasks.
Selected features:
-
Data modeling based on SDMX 3.0 standard.
-
Data collection from various sources.
-
Data transformation using Python code with debugging in a Web-based integrated development environment.
-
Data dissemination via public Web Portal and SDMX API.
-
Flexible data entitlements mechanism.
-
Data history tracking.
-
Survey engine.
-
Integrations with MS Excel, Jupyter, MS Power BI, and Power Automate.
Architecture Overview
QuantHub is designed as a highly customizable and configurable platform. Among its core components, are well-known open-source technologies such as Kubernetes, PostgreSQL, Elasticsearch, which allows it to be deployed on any cloud. The default implementation of QuantHub components can be extended or even replaced with customized ones to fit specific business needs.
The below diagram illustrates the architecture of QuantHub on a high level when being deployed to Azure.

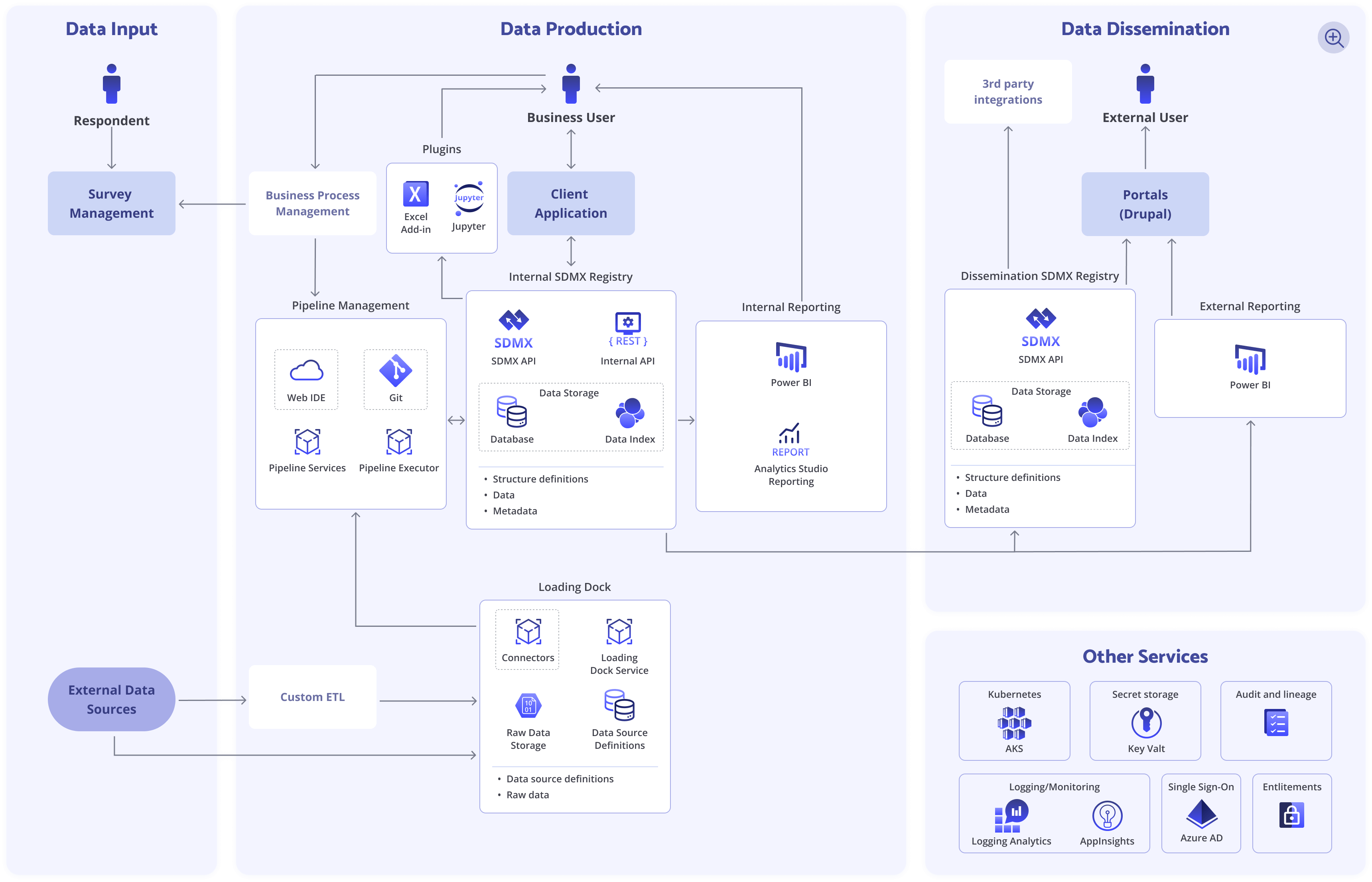
QuantHub ecosystem is comprised of Java services running as containers on a Kubernetes cluster. Most of the services are stateless, which, in conjunction with deployment to Kubernetes, enables their scalability and availability. Storage technologies have advanced scalability and availability as well.
QuantHub adheres to Secure SDLC principles with continuous security checks embedded into every step of the development process. They include both a thorough analysis and elimination of threats, as well as a verification of the implementation of these measures.
System Components
Data Input
Data can be ingested into QuantHub via Loading Dock and Survey Engine components.
Loading Dock
Loading Dock is a service that collects raw data from various external sources, aggregates it, and feeds to pipeline services for further processing. It is a primary data gateway that handles all the complexity of interaction with internal and external data sources.
Apart from being a single point of access for ingestion pipelines, Loading Dock tracks data source snapshots and provides means of data preparation, such as unpivoting and adding calculated columns to data streams.
Loading Dock can be extended with custom plugins to ingest data from any data sources not supported by QuantHub out of the box. Besides that, external ETL tools can be used to convert data into any of the formats supported by QuantHub. For example, if QuantHub does not support Oracle as a data source, Azure Data Factory, Amazon Data Pipeline or any other alternative can be set up to convert the source data to CSV files, which can then be consumed by QuantHub.
Survey Management
Survey Management is a flexible survey engine that can generate surveys based on SDMX metadata artifacts and store the results in SDMX datasets. It supports a wide range of end-user devices, data formats, logical operations, conditional branching, pagination, and more. Use it to create tailored surveys at scale including population censuses, allowing to unlock valuable insights and collect data from diverse target groups.
Data Production
QuantHub enables organizations to seamlessly process, transform, and analyze large volumes of ingested data, while ensuring interoperability and data standardization. All data is stored in a centralized SDMX Registry and processed via pipelines configured and developed by QuantHub users.
SDMX Registry
SDMX Registry is an SDMX 3.0-compliant service with a pluggable storage mechanism, which allows building custom storage engines optimized for specific kinds of data and data handling scenarios.
The default storage mechanism is optimized for time-series data and supports change history tracking. It uses two data engines – Elasticsearch and PostgreSQL. PostgreSQL stores all data, while Elasticsearch holds only time-series attributes and is used to speed up time-series queries. When retrieving data, Elasticsearch is queried first to get a page of time-series identifiers, and then PostgreSQL is queried using these identifiers.
Pipeline Management
Pipeline Management is a set of services responsible for the management, execution, and debugging of data pipelines. A pipeline may consist of multiple steps, where each one is an instance of any of the pipeline step types supported by the system:
-
Ingestion pipelines handle data copying from the sources registered in the Loading Dock to the SDMX registry.
-
Transformation pipelines run Python routines that transform data in the SDMX registry.
-
System pipelines run system tasks such as artifact import/export, publication to Portal, or any custom plugins implemented in terms of QuantHub customization.
System pipelines are pluggable and can be extended with custom logic, such as publishing data to any external systems not supported by QuantHub.
Pipelines are built as Docker images based on the configuration specified by users in the Data Production Web Application and then run on a separate “pipeline” pool of the QuantHub Kubernetes cluster.
Data Production Web Application
A Web application with access to QuantHub data management features such as Loading Dock, SDMX Artifact Management, Pipeline Management, and Analytics Studio.
Administration Web Application
A Web application with access to the administrative part of the QuantHub platform such as Data Entitlements Management, Audit, Plugin Management, etc.
Data Dissemination
QuantHub enables organizations to efficiently share their data with a wide range of stakeholders, including internal teams, external partners, and the public, while promoting transparency and accessibility.
Web Portal
A Drupal-based Web Portal that combines the flexibility to create content of Drupal with custom QuantHub-specific components to view and publish datasets.
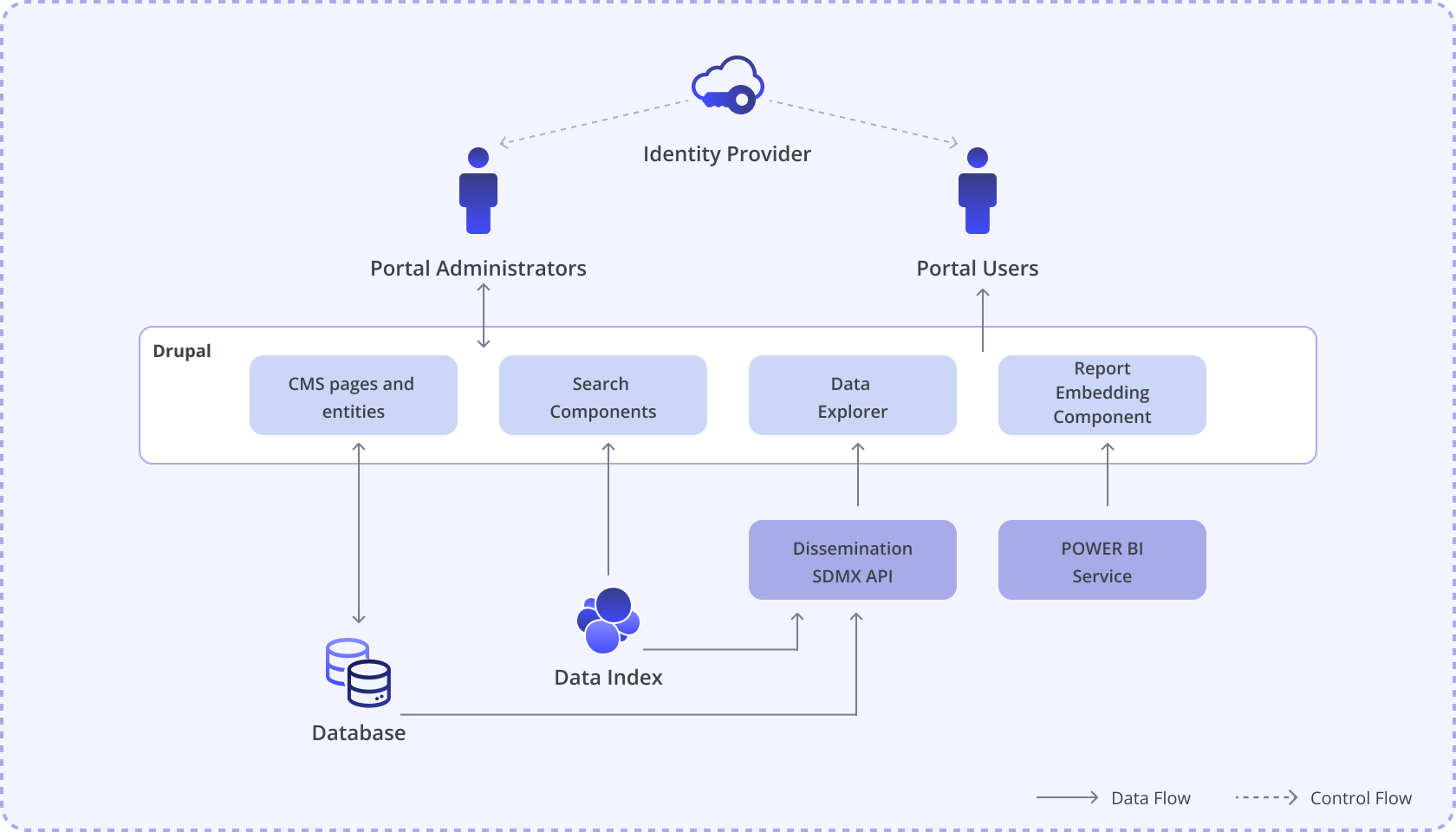
Portal has a dedicated instance of SDMX Registry, with copies of all published datasets. Data Explorer component of Portal has access to this instance of SDMX Registry.
Drupal uses PostgreSQL as primary storage and Elasticsearch to power the search functionality, so the same data storage instances can be used by both the Portal engine and the dissemination SDMX Registry.
Portal supports any OpenID-compatible Security Token Service for authentication such as Keycloak, Identity Server, Azure AD, Azure AD B2C, etc.
Public SDMX API
QuantHub public SDMX API offers standardized and efficient access to statistical data. Leveraging the Statistical Data and Metadata eXchange (SDMX) frameworks, it enables a quick retrieval of data sets from various platforms and systems.
MS Power BI
QuantHub includes a custom MS Power BI connector to facilitate the transfer of data from QuantHub into MS Power BI for visualization and analysis. The solution includes an automated pipeline step that simplifies the importing of data into MS Power BI. It generates an MS Power BI model based on the SDMX definitions of the data sets being exported from QuantHub and gives some control over the resulting model contents: data filtering, partitioning, hierarchies, etc.
MS Excel add-in
Use this add-in to access and import data from QuantHub data sets directly into MS Excel spreadsheets. Leveraging the MS Excel JavaScript API, it ensures compatibility across Windows, Mac, and MS Excel online platforms.
Integrations
QuantHub includes components that provide integrations with third-party solutions:
-
Jupyter plugin offers a direct access to data stored within the platform, creating an intuitive data research environment. This powerful integration allows users to effortlessly manipulate and analyze data using the popular Pandas Python library, streamlining data exploration, and transforming insights into actionable results right from their Jupyter notebooks.
-
WEB IDE, powered by Eclipse Che, provides a sophisticated environment for debugging of transformation pipelines. This integrated development platform enables users to efficiently identify and resolve issues within data processing pipelines, optimizing performance, and ensuring the correctness of data transformation.
-
Power Automate connector facilitates seamless integration with Microsoft Power Automate, allowing to trigger QuantHub actions such as "Run a pipeline" or "Load a data source" directly from custom Power Automate workflows. It simplifies the automation of data processing tasks, streamlining operations, and reducing manual intervention.
Quality Attributes
Security
QuantHub prioritizes security, ensuring confidentiality, integrity, and availability of its data products. The platform incorporates strong authentication mechanisms based on the OpenID Connect protocol, row-level security, and Attribute-based Access Control (ABAC) principles, enabling centralized and granular management of access to sensitive information.
Scalability
Scalability is a core aspect of the QuantHub architecture, achieved through:
-
Containerization that allows for horizontal scaling of services.
-
Load balancing for an even distribution of incoming requests across available instances.
Integrability
Integrability of QuantHub is supported by the following design principles:
-
Modular architecture enables integration of new components and services.
-
Open standards ensure compatibility with a wide range of external systems.
-
API-driven approach fosters interoperability and data exchange between components and external systems.
Availability
High availability of QuantHub architecture is powered by these features:
-
Stateless services provide a quick recovery from failures and maintain continuity.
-
Redundancy enables automatic failover support in case of a component failure.
-
Monitoring and health checks are in place for proactive identification and resolution of potential issues.